系列產品一覽 |
| |
|
| |
| |
| |
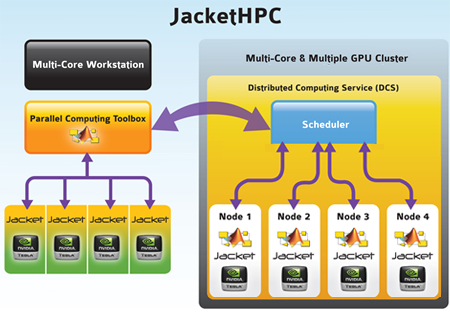
Multi-GPU Option - Multiple Nodes
Jacket HPC delivers unprecedented ability to transparently scale GPU computing across cluster. When a single host is not capable of driving more GPUs, simply add GPUs to another host on the network and Jacket HPC will take care of the rest. CPU clusters may be upgraded through the installation of GPUs, significantly increasing the cluster's computational capability without investing in new development for specialized GPU code.
Jacket HPC is targeted at the GPU cluster market. Distributed clusters of GPUs, that contain more than eight (8) GPUs, are well suited for Jacket HPC.
|
| |
|
| |
| Jacket HPC is built atop the Parallel Computing Toolbox (PCT) and Distributing Computing Server (DCS). PCT and DCS product licenses are required for executing Jacket HPC on network based HPC resources. With the addition of parallel constructs, such as PARFOR and SPMD, pre-existing code may be dispatched across all GPUs and CPUs in a cluster or a Cloud service. In many cases, little to no code revision is required to take advantage of this parallel computing capability. |
| |
 |
|
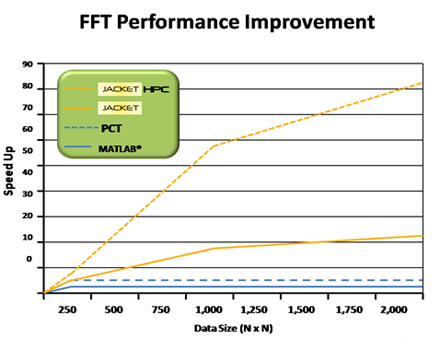
| Executing large scale codes with Jacket HPC and GPU clusters can dramatically accelerate time to solution while minimizing the programming time associated with leveraging these resources. For workstations or personal supercomputers, with 2 to 8 GPUs, Jacket MGL provides the functionality to fully leverage these resources. |
| |

